If a huge chunk of your internet felt broken yesterday, you weren’t alone. We all got a harsh reminder of how interconnected everything is when Amazon Web Services (AWS) had a massive outage that rippled across the web.
It all started in US-EAST-1, AWS’s oldest and biggest data hub in Northern Virginia. This one regional failure managed to expose just how fragile things are, knocking out over 2,000 companies and lighting up outage trackers with nearly 10 million reports.
The trouble, which kicked off around 3:11 AM ET, caused a world of financial pain and user frustration. We’re talking everything from social media and gaming to banking and even online classrooms. AWS’s own status page admitted to “elevated error rates” and “an operational issue,” saying they were “working on multiple parallel paths to accelerate recovery.”
It’s easy to hop on LinkedIn and point fingers, but let’s be honest, the blame game doesn’t help anyone. The real value is in the post-mortem. We need to dig into the cascade of failures to understand how one localized problem could boil up into a global meltdown.
The Domino Effect
So, how did one networking hiccup spiral completely out of control? It turns out, it all came down to central dependencies.
- The First Domino: DNS for DynamoDB. The problem first showed up as a DNS resolution failure for DynamoDB in US-EAST-1. A bad update to its API caused DNS servers to flake out. As one expert put it, it was like the internet had “temporary amnesia”—the data was safe, but no one could find the path to it.
- The Cascade. Once DynamoDB was in trouble, the dominoes fell fast. Critical infrastructure that leans on US-EAST-1, like IAM (for identity) and DynamoDB Global Tables, started having issues, too.
- The Spread to EC2 and Lambda. From there, the problem hammered an internal system that EC2 uses to launch new instances. This, in turn, caused EC2 (virtual servers) and Lambda (serverless functions) to start failing. AWS later said the root issue was an internal subsystem that monitors network load balancers.
- The Slow, Painful Recovery. AWS finally spotted the DNS trigger at 3:26 PM ET and fixed it by 5:24 AM ET. But the recovery was anything but instant. They had to start throttling operations—like new EC2 launches and Lambda invocations—just to get things stable. Customers were told to flush their DNS caches and hope for the best. It wasn’t until 6:01 PM ET that AWS gave the “all clear.”
The Impact and the Lesson
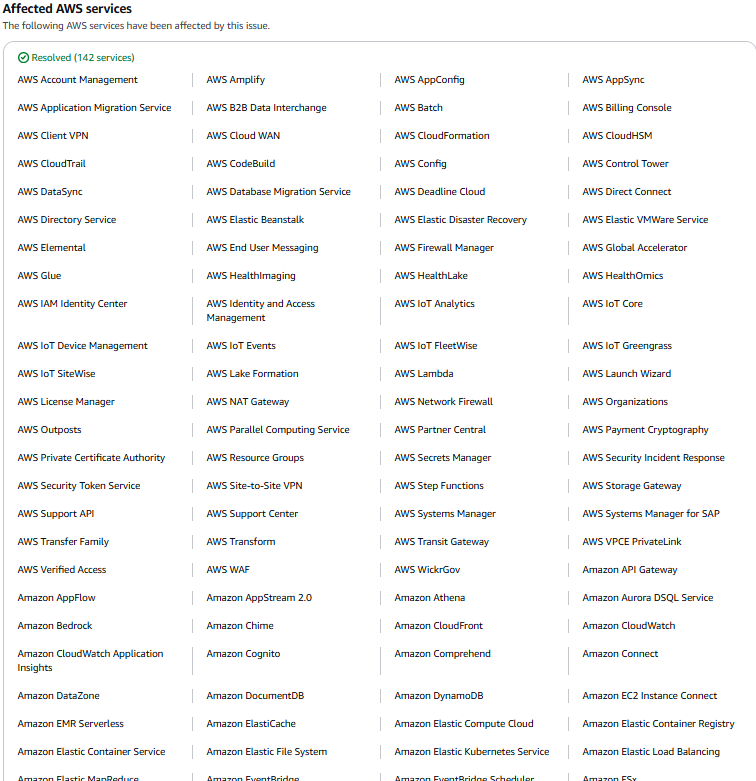
The sheer number of services that went down is staggering. We’re talking 142 different AWS services. This hit Amazon’s own stuff (Amazon.com, Prime Video, Alexa, Ring) and a “who’s who” of the internet: Snapchat, Venmo, Fortnite, Perplexity AI, Reddit, Lyft, and Canvas (the learning platform used by countless schools). It even reached across the pond, affecting the UK’s Lloyds Bank and the British government’s HMRC website.
An IT professor put it perfectly: “When a major cloud provider sneezes, the Internet catches a cold.” He’s not wrong. This just highlights our dangerous dependency on a handful of cloud providers.
What We Should All Take Away from This
The biggest takeaway for me is simple: Failure is always an option, even for giants like AWS. US-EAST-1 is a critical hub for so much of the web, and this outage proves that one failure can and will cascade.
If you’re building on the cloud, this outage isn’t just a news story; it’s a list of homework. Here’s what we all need to be doing:
- Decouple Your Stuff: Stop assuming the cloud provider has decoupled everything for you. They haven’t. You have to actively break those global dependencies yourself.
- Redundancy Isn’t Optional: Relying on a single region is just asking for trouble.
- This means using multiple availability zones and multiple regions.
- Cross-region replication needs to be in your budget from day one, not a “nice-to-have” you’ll get to later.
- Avoid the old ‘main site’ and ‘backup site’ model. Instead, deploy your applications so they are ‘active-active’, running live and serving traffic from multiple regions at once
- Get Serious About Disaster Recovery (DR): Your DR plan has to be able to survive a whole core region dying. This means having failover strategies that go way beyond what the standard cloud SLAs promise.
- Harden Your DNS: Since DNS started this fire, your own DNS infrastructure needs to be rock-solid, with its own failovers and monitoring.
- Maybe It’s Time for Multi-Cloud: Yesterday’s mess makes a multi-cloud architecture look less like a complex, “nice-to-have” option and more like a “must-have” requirement for true resilience.
This was a world-wide wake-up call. We have to build for resilience and plan for the fact that, yes, even the cloud will break.
The Human Element vs Age of AI
As soon as the outage hit, the internet started connecting some dots. It didn’t take long for people to bring up the AWS layoffs from a few months ago.
These weren’t just any layoffs. They hit the cloud computing unit, and they came right after CEO Andy Jassy warned that adopting generative AI would trigger job cuts across the company. The word is that AWS is all-in on using GenAI to “streamline operations and reduce headcount,” aiming to save costs and cut reliance on human workers. Some of the people let go were the “specialists” who work directly with customers on new products.
Look, AI is an amazing tool. It can absolutely accelerate development and infrastructure teams. But that’s what it should be: a tool. Not a replacement for human understanding and intuition, especially when you’re dealing with infrastructure this massive and interconnected.
Now, to be clear: AWS has not confirmed or denied that AI was a contributor to this specific incident. But the timing is… interesting. It’s a sharp reminder that for every super-sophisticated system running the internet, there’s a human (or team of humans) ultimately behind it, making it work.
The IBM Tale
Amazon isn’t alone in this “replace, don’t augment” mindset. If we want to see how this can go wrong, we just have to look at IBM for a cautionary tale.
IBM reportedly laid off 8,000 employees, mostly in HR, citing AI-driven automation. The plan was to let AI agents handle all the repetitive admin tasks.
And it worked… for a bit. The AI assistant (dubbed AskHR) automated 94% of inquiries and satisfaction scores actually went up. But that last 6%—the tricky, nuanced, human stuff like sensitive workplace issues or ethical problems—AI just couldn’t handle it. It needs human empathy and discretion.
In the end, IBM had to rehire staff. They learned the hard way that they had “underestimated what only humans can do.”
A take-away lesson is that AI is fantastic for the routine, predictable jobs. But it cannot replace human insight, critical thinking, or strategic, complex conversations. The real challenge for companies is to use the savings from automation to invest in the roles that only people can do. We need to balance technology with the irreplaceable value of human expertise.
A Chat About the “AI Workforce”
This whole situation, especially the possibility of AI action, reminds me of a conversation I recently had with my Director. We were talking about how AI is, without a doubt, an incredible tool. It’s amazing for automating all the repetitive grunt work and even acts as a fantastic assistant for high-level engineering.
But then we got to the “but.” We both see the writing on the wall: many companies are going to charge headfirst down the path of replacing human employees with AI. Why bother hiring and managing a person when you can just subscribe to a service, right? This is where it gets dangerous. This way of thinking will effectively eliminate a huge number of junior-level jobs. The industry will be left with senior engineers focusing on complex architecture and, ironically, managing the AI.
The problem is, what happens in 10 or 15 years when that generation of senior engineers retires?
Who is going to replace them?
If we get rid of the junior roles, we get rid of the training pipeline. You don’t just become a senior engineer. You get there by climbing the ladder, learning from mistakes, and getting mentored in those very junior jobs that companies are so eager to automate away. This is a case of short-term cost-cutting that leads to a massive, long-term talent gap. Keeping a steady human workforce isn’t just about ‘being nice’; it’s a critical strategy. It ensures we always have a bench of well-trained, experienced people ready to step up and solve the problems we haven’t even thought of yet.